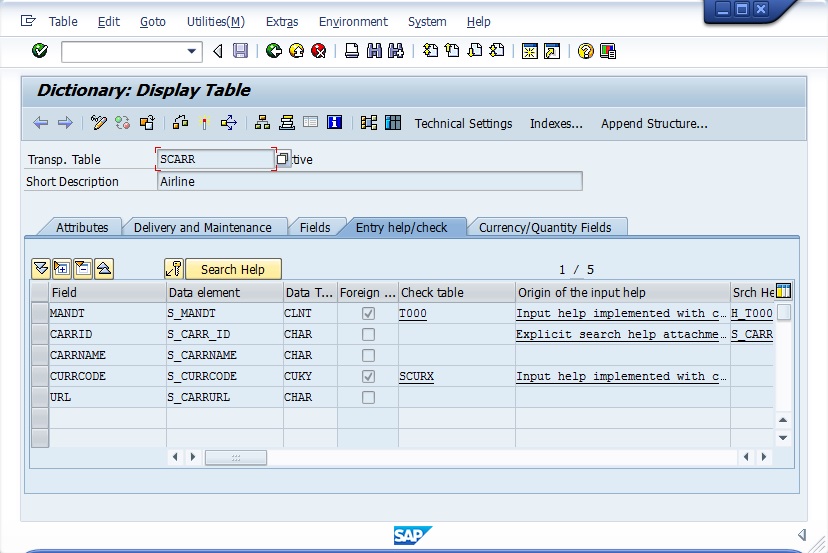
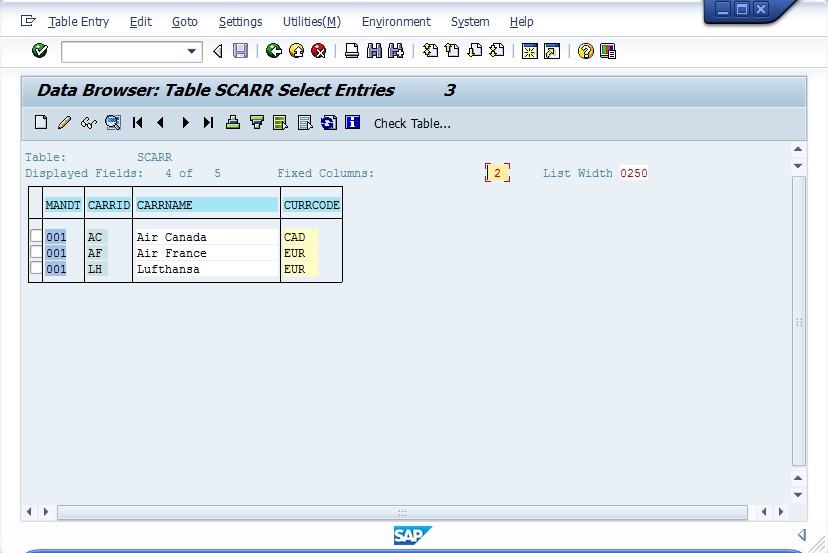
Você gerencia os seus projetos de desenvolvimento em um único ambiente integrado em tempo real? O Team Development encarrega-se especialmente do desenvolvimento da equipe e facilita a gestão do processo de desenvolvimento de aplicações. É uma ferramenta completa para gerenciar seu time de desenvolvedores, além de rastrear recursos, executar tarefas, marcar etapas, gerenciar os erros e muito mais. Através de comentários se obtém o feedback do usuário e, em seguida, pode-se classificar os comentários de usuários como recursos, para realizar novas tarefas e ou correção de erros. O Team Development possui cinco ferramentas com vários recursos para lhe ajudar a manter seus projetos e sua equipe de desenvolvimento.
Team Developement
- Features – Possibilita a criação de novas características da aplicação e também rastrear as funcionalidade da sua aplicação desde a concepção inicial até a implementação. Os recursos podem ser organizados pela liberação, atribuídos a desenvolvedores, etiquetados, associado a marcos e etc.
- Milestones – São marcos, permitem a marcação e o acompanhamento de eventos. recursos, erros, e lista de tarefas.
- To Dos – Criam tarefas e são nada mais que itens de ação que podem ser atribuídos, priorizados, marcados e controlados.
- Bugs – São itens criados para controlar defeitos de software. Erros podem ser atribuídos, associados à marcos, e acompanhados por data de vencimento, status e vários outros atributos.
- Feedback – São ligações ou sugestões que podem ser incorporadas em aplicações declarativas via entrada pela barra de navegação, ou codificação de um link. Usuários que executam uma aplicação podem, então, fornecer feedback, os usuários com acesso ao módulo de desenvolvimento da equipe dentro do Oracle Application Express podem gerenciar os feedbacks. O feedback pode ser convertido em um bug, em uma tarefa, uma entrada ou uma nova característica.
Utilizando o Team Development
O Apex conta com o conceito de usuários e grupos, os usuários são divididos em três categorias, os administradores que podem criar e modificar aplicações e objetos do banco de dados, os desenvolvedores que podem modificar aplicações e objetos do banco de dados e o usuários finais que não possuem privilégios de desenvolvimento, podem apenas acessar aplicações que não utilizam autenticação de um esquema externo. Todos os usuários estão integrados e podem ser geridos a partir do Team Developer.
Para a introdução a está ferramenta vamos utilizar o conceito de tarefas no qual é muito semelhante ao uso do popular MS Project, onde o gerente de projeto pode criar as clássicas tarefas com a porcentagem do andamento, tempo estimado de execução e atribui-las a determinado recurso, porem no Team Development não trabalhamos em uma planilha Standalone que é compartilhada e sim em um ambiente online totalmente integrado que dispensa o uso de ferramentas externas.
1 – Acesse o menu Team Development e clique em To Dos:

Team Development
2 – Clique em Create To Do para criar uma nova tarefa:
Tarefas
3 – Uma tarefa consiste em vários itens como, a ação da tarefa, a quem a tarefa esta associada, o colaborador da tarefa, data de inicio, data estimada de termino e data do termino da tarefa:

Ação da Tarefa
4 – Rolando a pagina mais abaixo encontramos os detalhes da tarefa como, versão, categoria, descrição, contexto da aplicação e pagina:

Detalhes da tarefa
5 – Mais abaixo se encontra, o marco da tarefa se estiver associado a um, as características da tarefa se estiver associada a uma, as etiquetas da tarefa e a estimativa de horas para a realização da tarefa.
Contexto e Estimativas
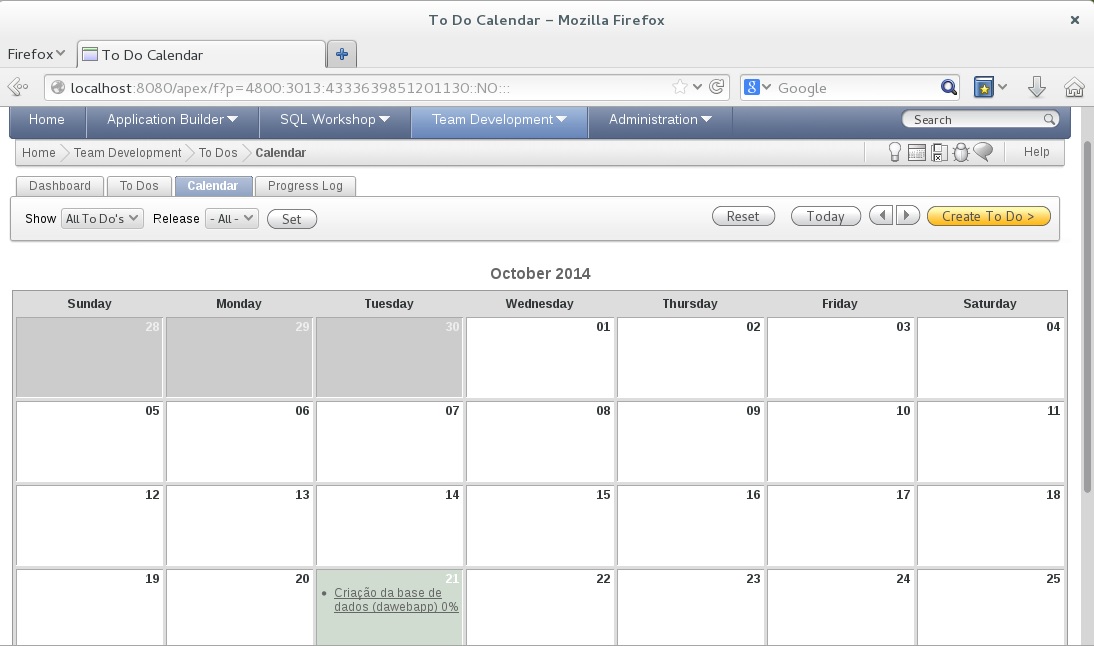
6 – Logo após a tarefa ser criada você pode gerencia-la como desejar, pode ainda se obter vários tipos de visualizações da lista de tarefas como por exemplo, em um calendário:
Lista de Tarefas
O Team Development é uma poderosa e completa ferramenta on-line para gerenciamento de todas as etapas do seu projeto, possibilitando interação com todos os tipos de usuários em tempo real. Para saber mais sobre o Team Development clique aqui.
Para acessar o post anterior clique aqui.